TLDR of Argmin's Summary of Half of the Meehl Lectures
Tags: ai, pompousness, Date: 2024-05-22
Over at argmin.net, Ben Recht is reflecting on Meehl's lectures on the metatheory of science, which is about how science progresses. The original lectures are fascinating but also long as well as long-winded, and I found Ben's blog series a much better read (especially since the originals are video recordings). Still, at the time of writing, with 13 blog posts covering less than half of the lectures (5/12), no self-respecting 21st century scientist can risk the time investment (equivalent to publishing 0.25 papers in machine learning) or – even worse – getting slowed down by methodological considerations.
... read the rest of TLDR of Argmin's Summary of Half of the Meehl Lectures.
Practitioner's Guide to Two-Tailed Averaging
Tags: ai, Date: 2022-12-06
This is a complement to the Two-Tailed Averaging paper, approached from the direction of what I think is a fairly common technique: averaging checkpoints.
We want to speed up training and improve generalization. One way to do that is by averaging weights from optimization, and that's a big win (e.g. 1, 2, 3). For example, while training a language model for the down-stream task of summarization, we can save checkpoints periodically and average the model weights from the last 10 or so checkpoints to produce the final solution. This is pretty much what Stochastic Weight Averaging (SWA) does.
... read the rest of Practitioner's Guide to Two-Tailed Averaging.
On the Design of Matrix Libraries
Tags: ai, lisp, Date: 2015-02-26
2020-05-03 – Things have changed the during last 5 years. This is a non-issue in Tensorflow and possibly in other frameworks, as well.
I believe there is one design decision in MGL-MAT that has far reaching consequences: to make a single matrix object capable of storing multiple representations of the same data and let operations decide which representation to use based on what's the most convenient or efficient, without having to even know about all the possible representations.
... read the rest of On the Design of Matrix Libraries.
Recurrent Nets
Tags: ai, lisp, Date: 2015-01-19
I've been cleaning up and documenting MGL for quite some time now, and while it's nowhere near done, a good portion of the code has been overhauled in the process. There are new additions such as the Adam optimizer and Recurrent Neural Nets. My efforts were mainly only the backprop stuff and I think the definition of feed-forward:
... read the rest of Recurrent Nets.
Higgs Boson Challenge Bits and Pieces
Tags: ai, lisp, Date: 2014-09-23
The Higgs Boson contest on Kaggle has ended. Sticking to my word at ELS 2014, I released some code that came about during these long four months.
... read the rest of Higgs Boson Challenge Bits and Pieces.
Higgs Boson Challenge Post-Mortem
Tags: ai, lisp, Date: 2014-09-23
Actually, I'll only link to the post-mortem I wrote in the forum. There is a also a model description included in the git repo. A stand-alone distribution with all library dependencies and an x86-64 linux precompiled binary is also available.
This has been the Kaggle competition that attracted the most contestants so it feels really good to come out on top although there was an element of luck involved due to the choice of evaluation metric and the amount of data available. The organizers did a great job explaining the physics, why there is no more data, motivating the choice of evaluation metric, and being prompt in communication in general.
... read the rest of Higgs Boson Challenge Post-Mortem.
Liblinear Support Added to cl-libsvm
Tags: ai, lisp, Date: 2013-04-09
In addition to the cl-libsvm asdf system, there is now another asdf system in the cl-libsvm library: cl-liblinear that, predictably enough, is a wrapper for liblinear. The API is similar to that of cl-libsvm.
Stackoverflow Post-Mortem
Tags: ai, lisp, Date: 2013-04-09
After almost two years without a single competition, last September I decided to enter the Stackoverflow contest on Kaggle. It was a straightforward text classification problem with extremely unbalanced classes.
... read the rest of Stackoverflow Post-Mortem.
Alpha–Beta
Tags: ai, lisp, Date: 2010-12-27
It hasn't even been a year yet since I first promised that alpha–beta snippet, and it is already added to Micmac in all its 35 line glory. The good thing about not rushing it out the door is that it saw a bit more use. For a tutorialish tic-tac-toe example see test/test-game-theory.lisp.
The logging code in the example produces
output, which is suitable for cut
and pasting into an org-mode buffer and exploring it by TABbing
into subtrees to answer the perpetual 'What the hell was it
thinking?!' question.
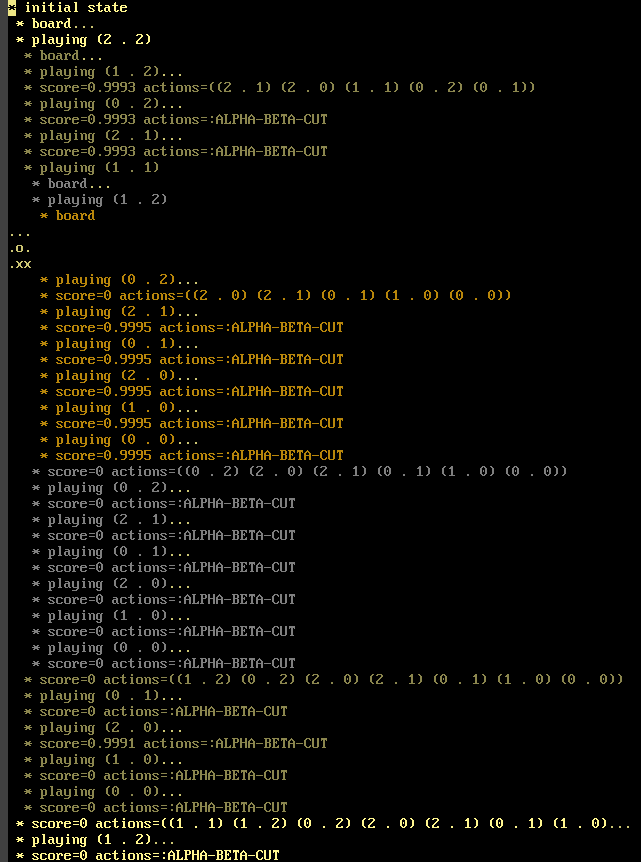{kind=link}
Nash Equilibrium Finder
Tags: ai, lisp, Date: 2010-12-26
While I seem to be unable to make my mind up on a good interface to alpha–beta with a few bells and whistles, I added a Nash equilibrium finder to Micmac, which is becoming less statistics oriented. This was one of the many things in Planet Wars that never really made it.
... read the rest of Nash Equilibrium Finder.
Planet Wars Post-Mortem
Tags: ai, lisp, Date: 2010-12-01
I can't believe I won.
I can't believe I won decisively at all.
The lead in the last month or so was an indicator of having good chances, but there was a huge shuffling of ranks in the last week and some last minute casualties.
... read the rest of Planet Wars Post-Mortem.
Important Update to the Planet Wars Starter Package
Tags: ai, lisp, Date: 2010-10-25
First, is it possible to get something as simple
as RESOLVE-BATTLE wrong? Apparently, yes. That's what one gets for
trying to port Python code that's pretty foreign in the sense of
being far from the way I'd write it.
... read the rest of Important Update to the Planet Wars Starter Package.
Planet Wars Common Lisp Starter Package Actually Works
Tags: ai, lisp, Date: 2010-09-21
Released
v0.6 (git,
latest
tarball).
The way the server compiles lisp submissions was fixed, and this
revealed a problem where MyBot.lisp redirected *STANDARD-OUTPUT*
to *ERROR-OUTPUT* causing the server to think compilation failed.
Planet Wars Common Lisp Starter Package
Tags: ai, lisp, Date: 2010-09-19
The Google AI Challenge is back with a new game that's supposed to be much harder than Tron was this spring. The branching factor of the game tree is enormous, which only means that straight minimax is out of question this time around. Whether some cleverness can bring the game within reach of conventional algorithms remains to be seen.
... read the rest of Planet Wars Common Lisp Starter Package.
UCT
Tags: ai, lisp, Date: 2010-03-19
As promised, my UCT
implementation is released, albeit somewhat belatedly. It's in
Micmac v0.0.1, see test/test-uct.lisp
for an example. Now I only owe you alpha–beta.